
White Paper
10 Principles of Effective Monitoring:
A Quick Checklist of Fundamentals
A Quick Checklist of Fundamentals
by Theo Schlossnagle
Whether you’re just beginning your monitoring journey or are a seasoned pro, being reminded of monitoring’s core principles is still helpful. This ebook highlights 10 essential monitoring tenets to live by.
#1: Don’t measure rates
You can derive the rate of change over time at query time.
The number one rule of monitoring is don’t ever measure rates — measure quantities.
For example, if you’re tracking packets per second out of an interface and miss a per-second measurement, then you’re in the dark. But if you’re measuring a count of total packets and at one second you’re at 700 billion packets, and then a second later you have 7,000,000,012 packets, then you know 12 packets have elapsed. What that means is that if you miss a measurement, you don’t know exactly how much you were sending during that time range, but you do know how much in total you sent during the expanded time range. You can always calculate rates from actual gauge values, but you cannot go backwards.
Let’s take CPU as another example. If your system is showing that CPU is 35% utilized, but behind the scenes it’s actually sending 30% over, then you’re getting the wrong answers. You need to be tracking CPU ticks. This is how Linux does it for instance — it tracks the number of centiseconds spent in state and it just counts up and up. If you want to know the rate over a specific amount of time, then you measure in the beginning, you measure the end, you subtract, and you divide by the time interval to calculate the rate per second. When you divide the number of elapsed centiseconds by the number of seconds, you get 100 times the rate, which is a percentage. So you should always monitor quantities of things and not rates.

#2: Monitor outside the tech stack
Your tech stack would not exist without happy customers and a sales pipeline. Monitor that which is important to the health of your organization. If you’re only looking at your computers, then you’re probably not servicing your business very well. Whatever KPIs your business has around metrics and performance should be monitored. That data your marketing department is analyzing to determine if their campaigns are succeeding? It should be in your monitoring solution. If a system is completely burning but not impacting the business — yet half a percent of introduced packet loss in a switch is causing loss to your bottom line — then chances are you would prioritize the former issue over the latter if you didn’t have all business-related data in your monitoring system. A system broken and on fire always seems more important than some sort of smidge of a percentage somewhere, but the outcomes can be completely different.
#3: Do not silo data
The behavior of parts must be put in context. Correlating disparate systems and even business outcomes is critical. This principle is a perfect follow-up to the previous one — today’s IT organizations want everything distributed, but if you don’t have your data together, then you cannot correlate your systems and business outcomes. When you put all of the data in your architecture that monitors your systems, your databases, your users, your finances, etc. into a single spot, then you can start building whatever business questions, answers and solutions you need around that data in a single spot. This is why there’s been so much investment across the industry in building highly scalable time series databases.

#4: Value observation of real work over the measurement of synthesized work
There’s no reason you shouldn’t be observing the actual workload instead of the synthetic measurement or the synthetic by-product of it. Some organizations rely solely on synthetic work and even averaged measurements from that work, which by no means will come close to providing real, accurate insights.
Say you synthesize traffic to your website to ensure it’s meeting latency requirements. While there is value in this discussed in the following principle, this should never replace monitoring real user interaction with your website. You should be measuring the latency of every single real user request and using that analysis to guide your decision making. In fact, there’s a high probability that no real individual interaction will match averaged latencies derived from synthetic traffic. So always value the observation of real work and individual measurements over synthetic work and averaged measurements.
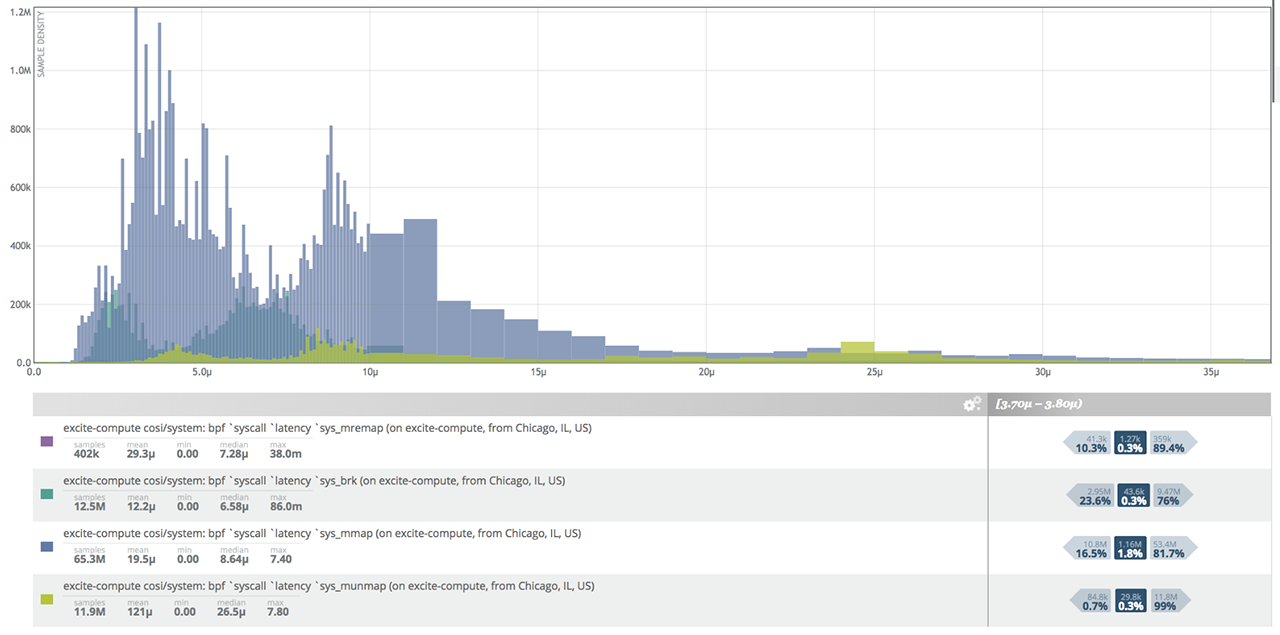
At Circonus, we use histograms to measure every latencies of all requests. The above graph is a Circonus histogram that includes 10 million latency samples, stored every five minutes.
#5: Synthesize work to ensure it functions for business-critical, low volume events
With the previous principle said, there is a time and place for synthesizing work. There are times where no one’s using a service; even the biggest sites in the world have APIs that get one hit every 15 minutes. You don’t want to learn for the first time that it’s broken when the first user shows up. Specifically in low volume environments, it is fundamental that you synthesize traffic to ensure the service is actually working.

#6: Percentiles are not histograms
For robust SLO management you need to store histograms for post-processing.
Percentiles are useful statistical aggregates that engineers often use for latency SLOs — but they should not be confused with histograms.
Example SLO: 95% of homepage requests should be served under 100 milliseconds over 28 days.
Example percentile: 95% of our website requests over the past 28 days had a latency of 98 milliseconds.
This percentile in and of itself does not yield any additional information beyond this number. For instance, it does not provide a distribution of latency data, like what the 97th or 98th percentiles are. A histogram, however, yields this and more.
A histogram is a representation of the distribution of a continuous variable, in which the entire range of values is divided into a series of intervals (or “bins”) and the representation displays how many values fall into each bin. Histograms are the best way to compute latency SLOs because they efficiently store all raw latency data and can easily calculate any percentile you would like to see. Want to see the 85th percentile? The 78th? The 94th? All of that is possible. Histograms visualize the distribution of latency data so engineers can easily identify disruptions and concentrations and ensure performance requirements are met.
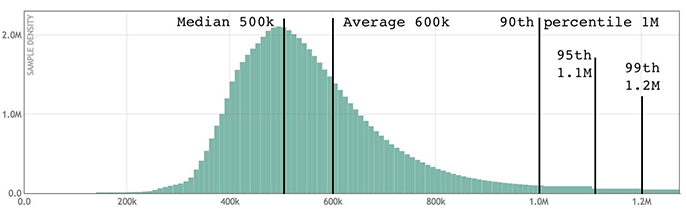
The above image is a Circonus histogram. It includes every single sample that has come in for a specific latency distribution — 6 million latency samples in total. It shows, for example, that 99% of latency samples are faster than 1.2 million microseconds.
#7: History is critical; not weeks or months, but years of detailed history
Capacity planning, retrospectives, comparative analysis, and modeling rely on accurate, high fidelity history.
A lot of monitoring vendors — particularly open source — downplay the importance of historical data. They store data for a month, believing anything older than that is not valuable. This couldn’t be more wrong. These solutions don’t store data long-term because they weren’t designed to — but that doesn’t mean it’s not important.
You should have years — not just weeks or months — of historical data that allows you to do postmortems. What’s key is that the data you collect today is the same tomorrow. Your minute-by-minute data or second-by-second data should be just that — not averaged into hour by hour or day by day over time as many solutions do. There is nothing more infuriating than to have a new question that comes out in the postmortem, but you no longer have the data you need to answer it. Do you remember that outage that you had six months ago? You would like to ask a question about that now that you didn’t ask then — but wait, you can’t because your graphs are just one big average over a day.
The data you have today should be exactly the same 6 months from now and 12 months from now. This is also critical for understanding capacity planning. You need granular data to do capacity planning over the long term. An example of this is bandwidth utilization.
You likely don’t serve the same bandwidth all day long. If you look at the history of bandwidth utilization and you’ve averaged it out over a day, then your maximum is completely obscured. All of the maximums are gone and you’re planning this trajectory curve that doesn’t accommodate your peaks at all. Having this granular data ensures you can answer all future questions correctly.
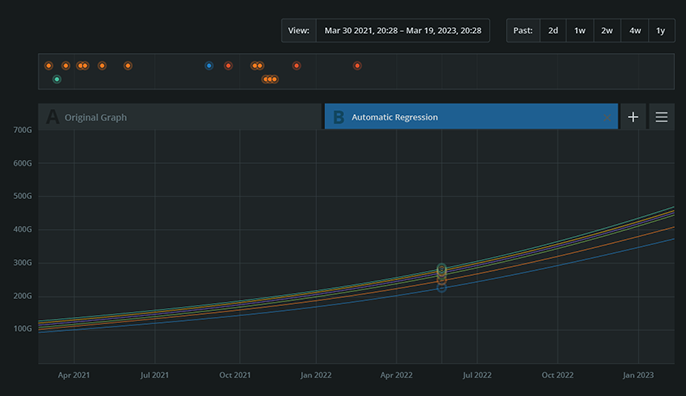
The above graph from Circonus is an example of how users can view long-term trends in growth, usage, seasonality or other business changes.
#8: Alerts require documentation
No ruleset should trigger an alert without: a human readable explanation, business impact description, remediation procedure and escalation documentation.
Every monitoring professional has suffered from alert fatigue. No product will save you from configuring alerts poorly — it takes human discipline to create only essential alerts. In my experience, though, I’ve identified rules you can attach to alerting that introduce enough burden to prevent engineers from writing unnecessary alerts.
For example, say you create an 85% disc space alert and you need to describe why this is important and what the business impact is while also including a full remediation procedure and list of key leaders or stakeholders that you need to talk to if something goes wrong. Once you attach these rules, it’s unlikely you would create an alert on 85% disc space.
You should not be alerting unless there’s an actual action that someone should be taking. Even in these cases, an automated action may be more relevant than an alert.

#9: Be outside the blast radius
The purpose of monitoring is to detect changes in behavior and assist in answering operational questions. This is one of the most common mistakes that I see in alerting architectures. Engineers set up alerting within the system, and the system breaks. So the actual outage that they are attempting to use monitoring to understand and remediate is inside the problem and they can’t use it or see anything until they’re back online again. It’s critical to move your data away from the problem so that when the system fails or malfunctions, your monitoring, alerting, visualizations and analytics systems are still available. In fact, monitoring solutions need to be more available than the systems they are monitoring, and they need to be outside the blast radius.

#10: Something is better than nothing
Don’t let perfect be the enemy of good. You have to start somewhere.
I often see engineers let perfect be the enemy of good, and there is no way you’re going to have perfect monitoring. It’s important to just get started, and it’s good to start at the top — those systems or services that most closely impact top level business indicators. If your organization is a user facing website, then egress traffic is likely the most significant and highly correlated surrogate measurement of success.
When determining where to begin monitoring, aim for those things that provide the highest value to your business. From there, you can explore monitoring further down to the bottom, to the point where you’re monitoring the latency of every IOP and service call. Once you get to this step, you can identify low hanging fruit that can yield massive performance improvements.

Practical Advice for Your Back Pocket
In our new era of microservices, distributed systems, and always-on expectations, monitoring has never been more critical to business success. It can be complex and overwhelming, but hopefully this checklist can provide some quick, practical and helpful assistance as you navigate through your monitoring journey.
If you’re ready to take your monitrong to the next level, start a free 60 day trial of Circonus. Monitor all of your metrics, apps, and infrastructure in one platform, and learn why customers like Major League Baseball, HBO, and Redfin switched to Circonus.
