Software is eating the world. Devices that run that software are ubiquitous and multiplying rapidly. Without adequate monitoring on these services, operators are mostly flying blind, either relying on customers to report issues or manually jumping on boxes and spot checking. Centralized collection of telemetry data is becoming even more important than it ever was. It is becoming significantly harder to monitor the volume of telemetry generated by the sheer number of devices and the increasingly elastic architecture of modern infrastructure. On top of this, your telemetry data store needs to be extremely reliable and performant in today’s world. The last thing you need while researching and diagnosing a production issue is for the stethoscope into your system to break down or introduce debilitating delays to diagnosing the problem. In a lot of ways, it is the most important piece of infrastructure you can run.
Circonus has been delivering a Time Series Database (TSDB) to our on-prem customers for many years, specifically architected to be reliable, scalable, and fast. Many of these on-prem customers run large installations with millions of time-series and Circonus’s TSDB has been meeting these demands for years. What has been missing up until today was the ability to ingest other sources of data, and to interoperate with other data collection tools and monitoring systems already in place.
Today, starting with Graphite, that is no longer a barrier.
Overview
IRONdb is Circonus’s internally developed TSDB, now with extensions to support the Graphite data format on ingestion and with interoperability with Graphite-web (and Grafana by extension). It is a drop-in solution for organizations struggling to scale Graphite or frustrated with maintaining a high availability metrics infrastructure during surges and outages and even routine maintenance. Highly scalable and robust, IRONdb has support for replication and clustering for redundancy of data, is multi-data center capable, and comes with a full suite of administration tools.
Features
- Replication – Don’t lose data during routine maintenance or outages.
- Multi-DC Capabilities – Don’t lose data if Amazon has an outage in us-east-1.
- Performance – It’s fast to write and equally fast to read.
- Data Robustness and compression – Keep more data and don’t worry about corruption.
- Administration tools – View system health and show op latencies.
- Graphite-web interoperability – Plug it right into your existing tooling.
Replication
One of the major issues with data management in Graphite or other time series databases is the management of nodes. If you lose a node or have to take it down intentionally for maintenance, what happens to all your data during this outage? Sadly, for many users of TSDBs, they live with the outage and any poll based alerts that happen to trigger are just part of the quirks of that system.
IRONdb completely side steps this problem by keeping multiple copies of your data in the cluster of IRONdb nodes. As data arrives, we store the data on the local node if we determine that it belongs there based on a consistent hash of the incoming metric name, and we also journal it out to other nodes based on your configuration settings for the number of copies you want to keep. We then replicate this data to the other nodes through a background thread process. You can see and hear more details about this process in Circonus Founder and CEO, Theo Schlossnagle’s talk on the Architecture of an Analytics and Storage Engine for Time Series Data.
The HTTP POST of data to the Graphite handler in IRONdb is guaranteed to not respond with a 200 OK until data has both been committed locally and written to the journals for the other nodes it belongs on.
The Graphite network listener cannot make these same claims because there is no acknowledgement mechanism in a plain network socket. It is provided for interoperability purposes, but keep in mind you can lose data if you employ this method of ingestion.
Multi Data Center Capabilities
As an extension of replication, IRONdb can be deployed in a sided configuration which makes it aware that a piece of data must reside on nodes on both sides of the topology.
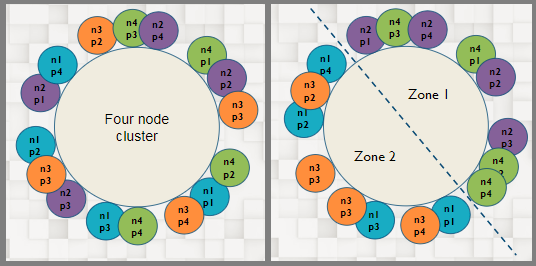
A piece of data which was destined for n2-2 in the above diagram would be guaranteed to be replicated to a node on the other side of the ring in “Availability Zone 2”. By setting up your IRONdb cluster in this way, you could lose an entire availability zone and still have all of your data available for querying and your cluster available for ingesting. When the downed nodes come back online, the journaled data that has been waiting for them is then replicated in the background until they catch back up.
Since IRONdb is a distributed database, it would not be complete if you had to know where the data was to ask for it. You can ask any node in the IRONdb cluster for a time series and range and it will satisfy as much of the query as it can using local data for performance reasons, and it will proxy to other nodes for time series that don’t live on that node. Keep in mind that in sided configurations where one side is geographically distant this can lead to the speed of light penalty for data fetches. We have plans in the pipeline to fix this weakness and to try to prefer local replicas if they exist, but for now, if your data centers are far apart and you use a sided config you will likely pay the speed of light RTT to proxy data fetches.
Performance
There are lies, damned lies, and benchmarks as the saying goes. I encourage you to take all of this with a grain of salt and also test for yourself. In the wild, the actual numbers you can achieve with IRONdb are dependent on hardware, your replication factor of data within the cluster, and what your data actually looks like on the way in.
All of that caveat aside, Influx data has created a nice benchmark suite to compare its time series database to other popular solutions in the open source world. This isn’t an exact analog to IRONdb because IRONdb does not yet support stream based tags (that is coming soon), but the test of ingestion speed with a fixed cardinality can be mimicked. Basically, I synthesized a Graphite metric name from the unique set of tags + fields + measurement name that the Influx benchmark suite uses. This ensured that IRONdb was ingesting the same unique set of metrics that influx-db, Cassandra, or OpenTSDB would ingest in the same test.
In the influx-data comparison of Influx-db vs. Cassandra, Cassandra achieved 100K metrics ingested per second and Influx achieved 470K metrics per second. I repeated this test using IRONdb:
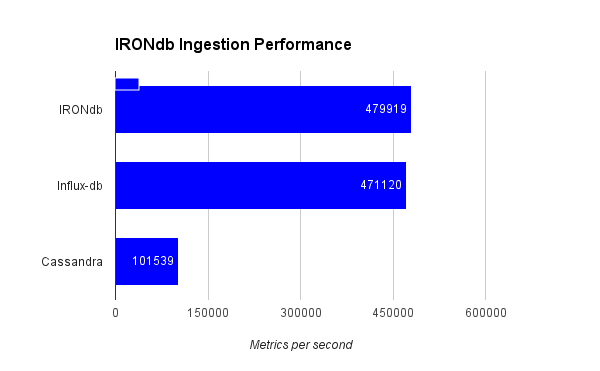
The Cassandra and Influx-db numbers were pulled from their original post. I did not repeat the benchmark for these other 2 databases on this hardware.
IRONdb (single node) is on the same scale of Influx-db for the same ingestion set and maybe slightly faster. There is no info in the original Influx-data post about the hardware this test was run on. This initial test was from a remote sender sending data to IRONdb over HTTP. I then repeated this test sending data from localhost on the IRONdb node itself:
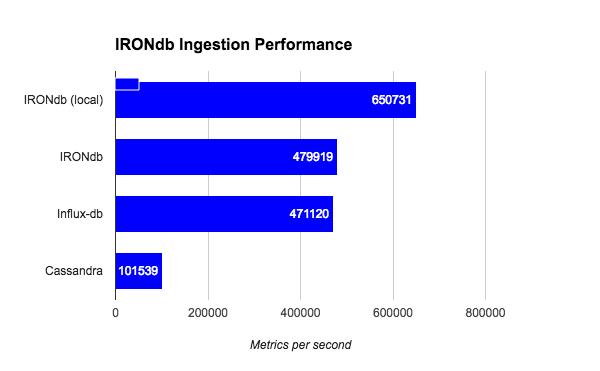
When eliminating the roundtrip penalty of the benchmark test suite, IRONdb goes significantly faster.
I ran the IRONdb test on a zone on a development box with the following configuration:
CPU:
root@circonus:/root# psrinfo -vp
The physical processor has 8 cores and 16 virtual processors (0-7 16-23)
The core has 2 virtual processors (0 16)
The core has 2 virtual processors (1 17)
The core has 2 virtual processors (2 18)
The core has 2 virtual processors (3 19)
The core has 2 virtual processors (4 20)
The core has 2 virtual processors (5 21)
The core has 2 virtual processors (6 22)
The core has 2 virtual processors (7 23)
x86 (GenuineIntel 306E4 family 6 model 62 step 4 clock 2600 MHz)
Intel(r) Xeon(r) CPU E5-2650 v2 @ 2.60GHz
The physical processor has 8 cores and 16 virtual processors (8-15 24-31)
The core has 2 virtual processors (8 24)
The core has 2 virtual processors (9 25)
The core has 2 virtual processors (10 26)
The core has 2 virtual processors (11 27)
The core has 2 virtual processors (12 28)
The core has 2 virtual processors (13 29)
The core has 2 virtual processors (14 30)
The core has 2 virtual processors (15 31)
x86 (GenuineIntel 306E4 family 6 model 62 step 4 clock 2600 MHz)
Intel(r) Xeon(r) CPU E5-2650 v2 @ 2.60GHz
Disk:
0. c0t5000CCA05CCEDCDDd0
/pci@0,0/pci8086,e06@2,2/pci1000,3020@0/iport@ff/disk@w5000cca05ccedcdd,0
1. c0t5000CCA05CCF8421d0
/pci@0,0/pci8086,e06@2,2/pci1000,3020@0/iport@ff/disk@w5000cca05ccf8421,0
2. c0t5000CCA07313BA35d0
/pci@0,0/pci8086,e06@2,2/pci1000,3020@0/iport@ff/disk@w5000cca07313ba35,0
3. c0t5000CCA073109B75d0
/pci@0,0/pci8086,e06@2,2/pci1000,3020@0/iport@ff/disk@w5000cca073109b75,0
4. c0t5000CCA073111CCDd0
/pci@0,0/pci8086,e06@2,2/pci1000,3020@0/iport@ff/disk@w5000cca073111ccd,0
5. c0t5000CCA073156BFDd0
/pci@0,0/pci8086,e06@2,2/pci1000,3020@0/iport@ff/disk@w5000cca073156bfd,0
...
9. c3t55CD2E404C53549Bd0
/scsi_vhci/disk@g55cd2e404c53549b
Configured in a 6 way stripe under ZFS with an L2ARC on a single SSD drive:
root@circonus:/root# zpool status data
pool: data
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
c0t5000CCA07313BA35d0 ONLINE 0 0 0
c0t5000CCA073156BFDd0 ONLINE 0 0 0
c0t5000CCA073111CCDd0 ONLINE 0 0 0
c0t5000CCA073109B75d0 ONLINE 0 0 0
c0t5000CCA05CCEDCDDd0 ONLINE 0 0 0
c0t5000CCA05CCF8421d0 ONLINE 0 0 0
cache
c3t55CD2E404C53549Bd0 ONLINE 0 0 0
The CPUs on this box were mostly bored during this ingestion test:
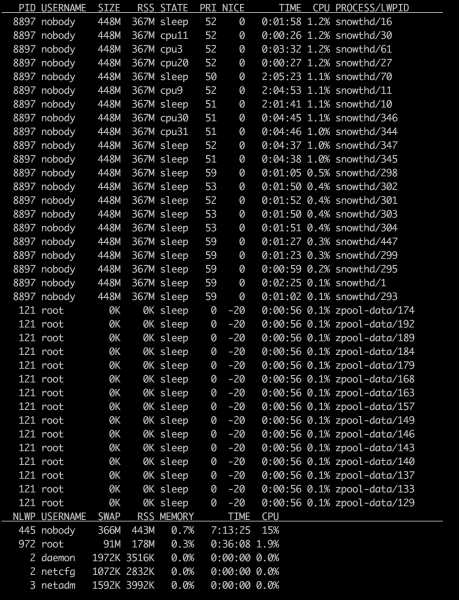
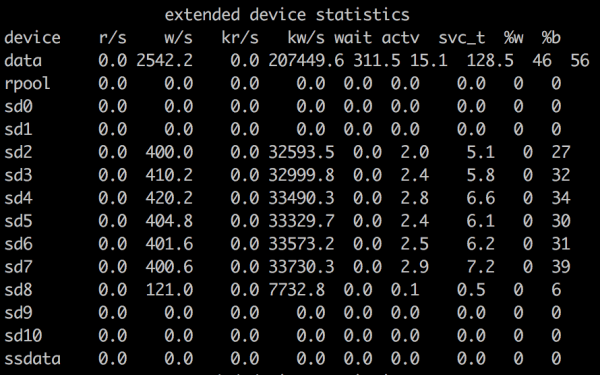
Being a 16 core box with hyper-threading on, there are 32 vCPUs to address here. The IRONdb process (called snowthd here) is eating about 5 of the cores (mostly in parsing the incoming ASCII text). The drives are pretty busy though:
Data Robustness and Compression
IRONdb runs on OmniOS. OmniOS uses ZFS as it’s file system. ZFS has many amazing features that keep your data safe and small. A few of the important ones:
“A 2012 research showed that neither any of the then-major and widespread filesystems (such as UFS, Ext,[12] XFS, JFS, or NTFS) nor hardware RAID (which has some issues with data integrity) provided sufficient protection against data corruption problems.[13][14][15][16] Initial research indicates that ZFS protects data better than earlier efforts.[17][18] It is also faster than UFS[19][20] and can be seen as its replacement.” – Wikipedia
“In addition to handling whole-disk failures, … can also detect and correct silent data corruption, offering “self-healing data”: when reading a … block, ZFS compares it against its checksum, and if the data disks did not return the right answer, ZFS reads the parity and then figures out which disk returned bad data. Then, it repairs the damaged data and returns good data to the requestor.” – Wikipedia
“ZFS is a 128-bit file system,[31][32] so it can address 1.84 × 1019 times more data than 64-bit systems such as Btrfs. The limitations of ZFS are designed to be so large that they should never be encountered in practice. For instance, fully populating a single zpool with 2128 bits of data would require 1024 3 TB hard disk drives.[33]” – Wikipedia
- Compression
“Transparent filesystem compression. Supports LZJB, gzip[55] and LZ4.” – Wikipedia
In the above ingestion test, the resultant data occupied 5 bytes per data point due to LZ4 compression enabled on the zpool that the data was written to.
Our CEO has written about this before.
Administration tools
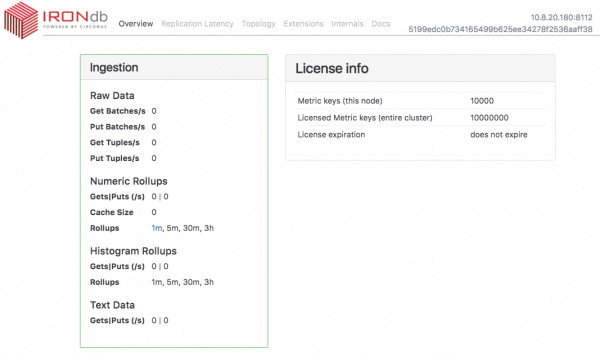
This admin UI gives you introspection into what each IRONdb node is doing. A thorough discussion of the Admin UI would require it’s own blog post, but at a high level you can see:
- Current ingest rates and storage space info
- Replication latency among nodes in the cluster
- The topology of the cluster
- Latency measurements of almost every single operation we perform in the database on the “Internals” tab
This last one also provides a nice histogram visualization of the distribution of each operation. Here is an example of the distribution of write operations for the Influx-data ingestion benchmark above:
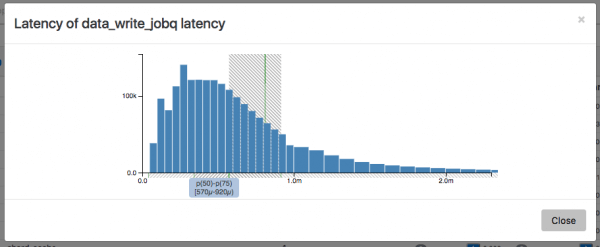
The 50th to 75th percentile band of write operation latency for batch PUTS to IRONdb was between 570µs and 920µs
Graphite-web Interoperability
IRONdb is compatible with Graphite-web 0.10 and above. We have written a storage finder plugin for use with Graphite-web. Simply install this plugin and configure it to point to one or more of your IRONdb nodes and you can render metrics right from Graphite-web:
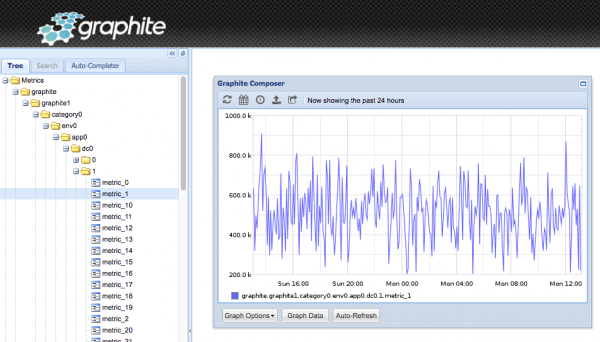
Or use Grafana with the Graphite datasource:
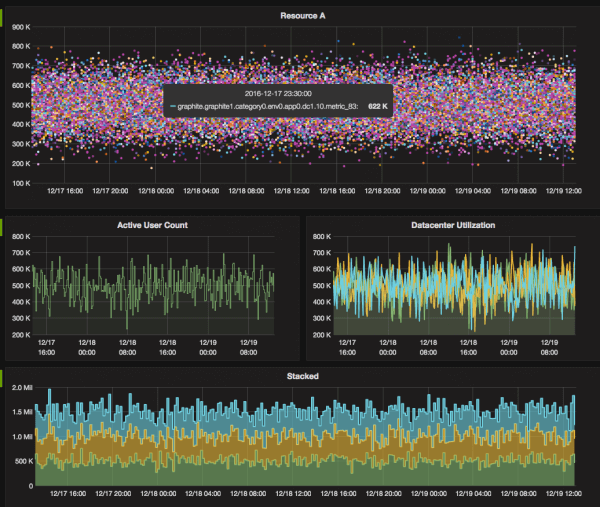
There is also a Grafana Datasource in the works which will expose even more of the power of IRONdb, so stay tuned!
tl;dr
IRONdb is a replacement for Whisper and Carbon-cache in Graphite that’s faster, more efficient, and easier to operate and scale.
Read the IRONdb Documentation or click below to sign up and install IRONdb today!